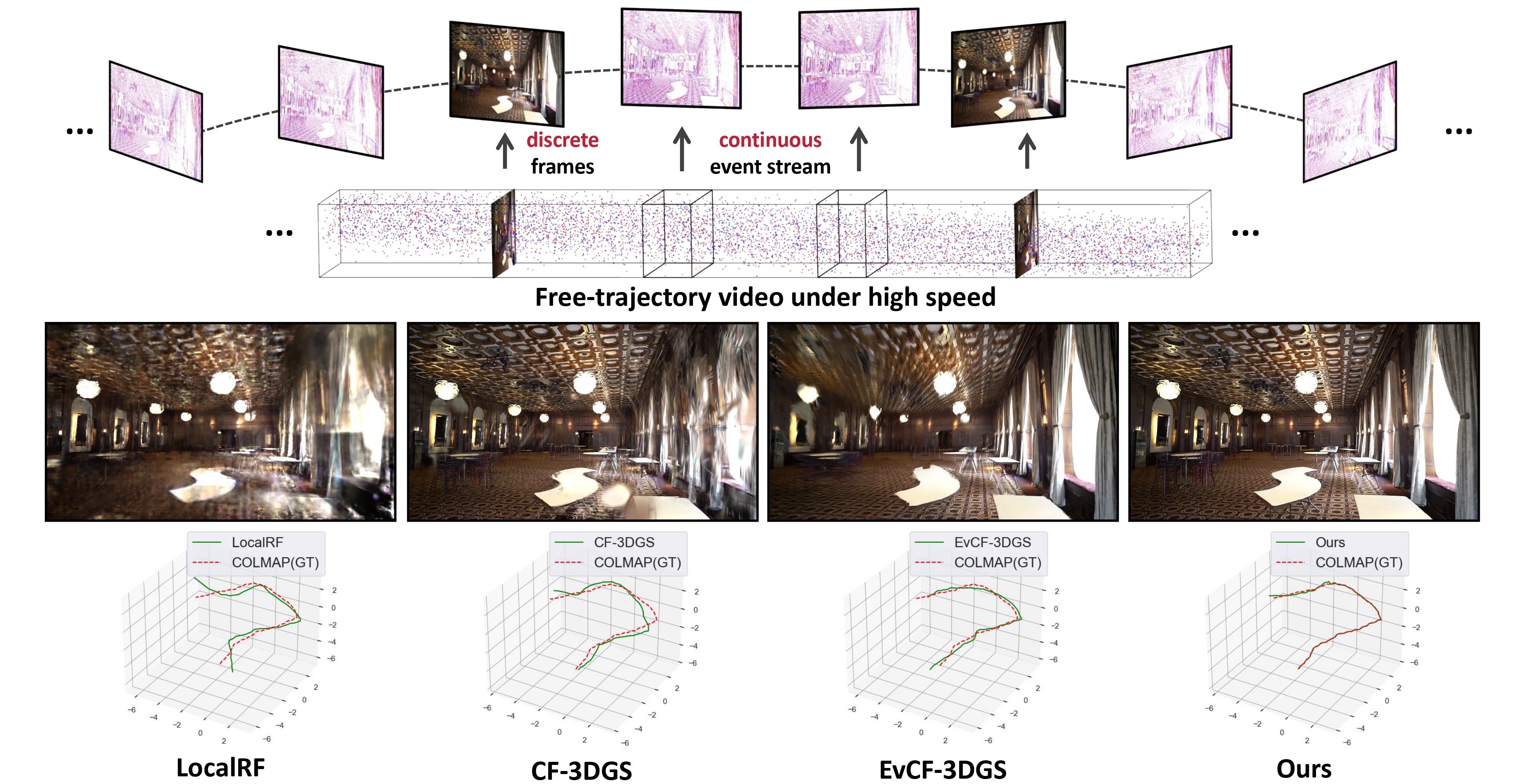
Scene reconstruction from casually captured videos has wide real-world applications. Despite recent progress, existing methods relying on traditional cameras tend to fail in high-speed scenarios due to insufficient observations and inaccurate pose estimation. Event cameras, inspired by biological vision, record pixel-wise intensity changes asynchronously with high temporal resolution and low latency, providing valuable scene and motion information in blind inter-frame intervals. In this paper, we introduce the event cameras to aid scene construction from a casually captured video for the first time, and propose Event-Aided Free-Trajectory 3DGS, called \textbf{EF-3DGS}, which seamlessly integrates the advantages of event cameras into 3DGS through three key components. First, we leverage the Event Generation Model (EGM) to fuse events and frames, enabling continuous supervision between discrete frames. Second, we extract motion information through Contrast Maximization (CMax) of warped events, which calibrates camera poses and provides gradient-domain constraints for 3DGS. Third, to address the absence of color information in events, we combine photometric bundle adjustment (PBA) with a Fixed-GS training strategy that separates structure and color optimization, effectively ensuring color consistency across different views. We evaluate our method on the public Tanks and Temples benchmark and a newly collected real-world dataset, RealEv-DAVIS. Our method achieves up to 3dB higher PSNR and 40% lower Absolute Trajectory Error (ATE) compared to state-of-the-art methods under challenging high-speed scenarios.
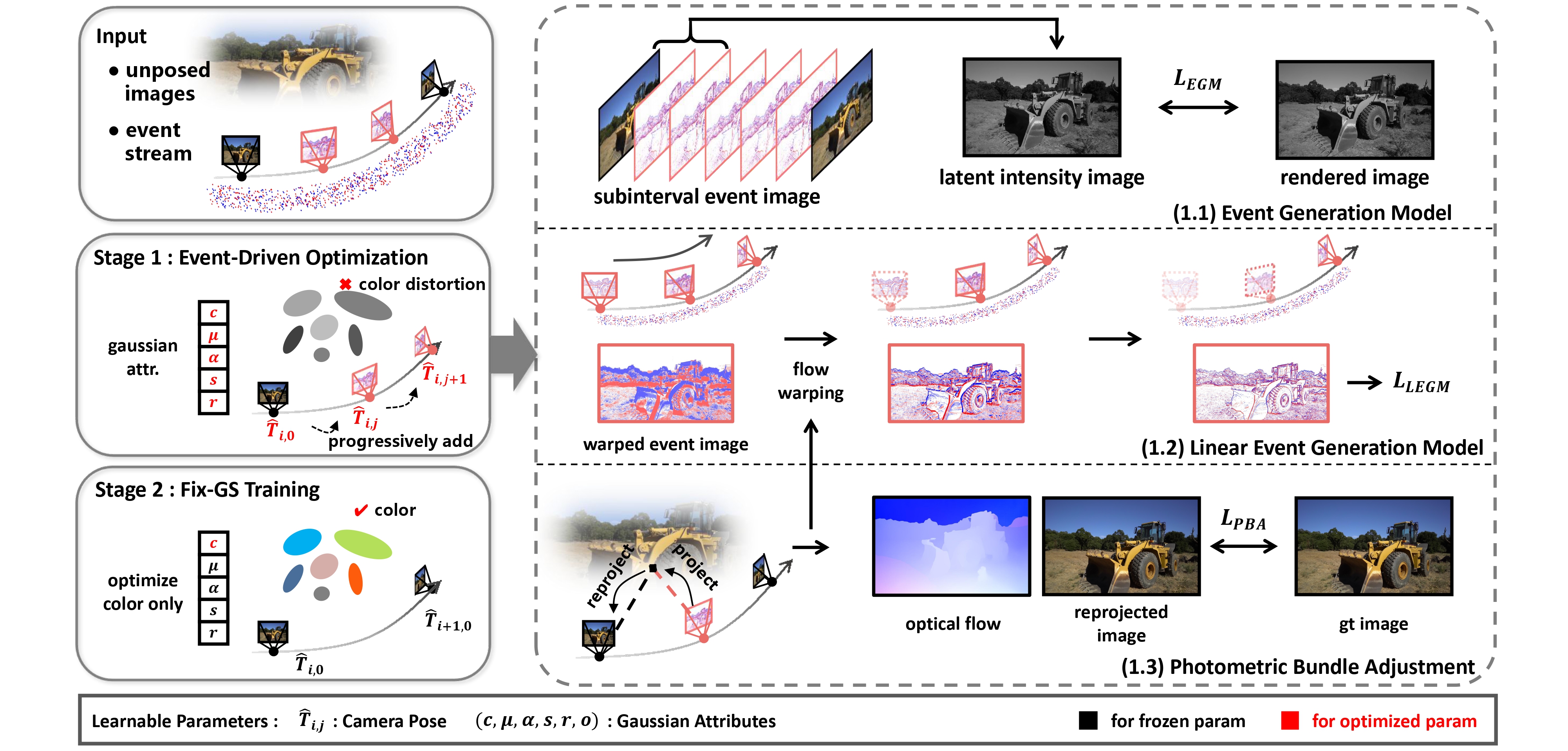
Method Overview. Our method takes video frames \( \{I_i\} \) and event stream \( \varepsilon = \{\mathbf{e}_k\} \) as input. During training, we random sample \( t \in \{t_{i,j}\} \), leveraging the events within current subinterval and most recent frame to establish the proposed three main constrains, \( \mathcal{L}_{EGM} \), \( \mathcal{L}_{LEGM} \), and \( \mathcal{L}_{PBA} \). The colored dots (red for positive and blue for negative events) represent the event data.
Comparisons on Tanks and Temples.
Comparisons on EvReal-DAVIS.
We visualise the estimated pose trajectories against ground truth trajectories.
Results on Tanks and Temples.
Results on EvReal-DAVIS.
To be updated